
Un Web Crawler in Java – I parte
Giugno 24, 2016Path Ascending Crawlers
Questo tipo di Crawler è utilizzato per scaricare più risorse possibile da un determinato sito Web e in particolare esplora ogni percorso (path) del sito Web di interesse. Per esempio, se “l’inizio” avviene con il link http://sitoprova.it/prova/esempi/inde.html, il Crawler prova ad esplorare /prova/esempi/, /prova/, e /. Questo significa che il tipo di Crawler in questione trova quelle risorse “isolate” che gli altri tipi di “ragni” non avrebbero potuto trovare. Questi Crawlers sono anche conosciuti con il nome di Web Harvesting Software che tradotto significa software di raccolta (ricerca) Web.
Random Walk
L’algoritmo Random Walk è utilizzato in diversi campi: dall’ecologia alla politica, dalla scienza dei computer alla biologia. Un esempio elementare di random walk è quello del lancio di una moneta. Partendo da un momento zero con una probabilità del 50% ho essenzialmente la possibilità di tracciare le due figure seguenti dopo tre lanci di una moneta:

Figura 4.
(L’algoritmo Random Walk)
Nel primo lancio ottengo testa (T) e attribuisco un valore +1. Nel secondo lancio ho il 50% di probabilità di ottenere +1(T) o -1(+). Al terzo lancio ho la possibilità di a seconda dell’esito del secondo lancio di ottenere diverse possibilità come descritto nell’immagine.
Se le primo lancio avessi ottenuto (+) il tutto si modifica e avrei ottenuto la seguente struttura ad albero con i percorsi così disegnati.
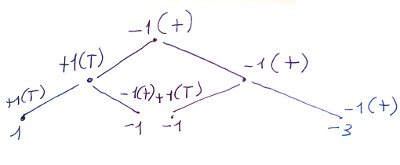
Figura 5.
(L’algoritmo Random Walk: il lancio di un moneta)
Come nel lancio della moneta così il Crawler si comporta nella ricerca delle pagine.
Focused o Targeted Crawling
Un focused crawler scarica solamente quelle pagine che ritiene “importanti” per un determinato argomento di ricerca o più argomenti evitando di scaricare quelle che non gli interessano. Il problema è quello di determinare nel Web ciò che è importante e nel minor tempo possibile.
Incremental Crawling
Questo tipo di Crawler permette di ottenere una “memoria” storica delle pagine di un sito Web. Data la dinamicità dei siti Web l’incremental Crawler passa una prima volta e “scarica” o “registra” tutte le pagine del sito web oggetto di scansione, e nelle volte successive esso registra le pagine eliminate, quelle modificate, quelle nuove e ovviamente quelle che non sono state cambiate.
I vari tipi di Crawlers e i metodi con cui indicizzano le pagine web sono ancora più “vari” e diversi da quelli fin qui descritti oppure si compongono di una o più modalità di scansione. In ultima analisi possiamo dire che più di modalità di scansione possiamo parlare di strategie, ma non essendo questa la sede di un approfondimento possiamo iniziare con la progettazione vera e propria di un Web Crawler nel prossimo articolo.
Come al solito, per eventuali domande e integrazioni inviate un e-mail a webmaster@megalinux.cloud. Aiutate a sostenere The Megalinux, l’unico sito nel Web senza pubblicità inviando Bitcoin al seguente indirizzo.
3LpoukFpvDHTZPn5qGbLwUzve3rX9zsSq6


