Il Formato OHLCV e il concetto di Timeframe.
In questo approccio useremo le API Pubbliche della libreria ccxt per poter scaricare i dati di interesse nel formato OHLCV. https://en.wikipedia.org/wiki/Open-high-low-close_chart
Ciò significa, che scaricheremo i valori di Apertura (Open), Massimo (High), Minimo (Low), Chiusura (Close) ed infine volume (Volume) per quanto concerne la pair ‘ETH/BTC’. Insieme a questi dati verrà scaricata anche la data di assegnazione dei valori, ossia il valore presente nella colonna Time del dataframe df1.
Esempio di riga di OHLCV:
[ [ 1504541580000, // UTC timestamp in millisecondi, integer 4278.4, // (O)pen price, di tipo float 4256.6, // (H)ighest price, di tipo float 4225.0, // (L)owest price, di tipo float 4212.7, // (C)losing price, di tipo float 36.72941912 // (V)olume di tipo float ], ... ]
Molto importante, è la definizione di un valore di timeframe. In pratica si tratta di definire, l’intervallo di tempo tra un riga di dati OHLCV e l’altra. Questi valori saranno a sua volta gestiti all’interno di un DataFrame.
Che cos’è un DataFrame?
Un DataFrame è una struttura a colonne, nel quale si può memorizzare qualsiasi oggetto. Essenzialmente il DataFrame è composto da tre elementi: Dati, Righe e Colonne. A prima vista possiamo equiparare un DataFrame come un foglio di OpenOffice Calc o Excel. Con l’installazione della libreria Pandas si hanno a disposizione strutture dati e strumenti per l’analisi dei dati come ad esempio il DataFrame.
La riga ventisette della figura due mi serve per “stampare” sulla console le prime n righe del DataFrame (default: 5).

(Visualizzazione delle prime cinque righe del dataframe).
Nell’immagine precedente, potete vedere, il risultato dell’istruzione df1.head(). Da destra a sinistra sono presenti: il numero di riga, la data (Time) impostato come indice del DataFrame, e rispettivamente le colonne “Open”, “High”,”Low”,”Close”,”Volume”. La colonna “Close” rappresenta il prezzo dell’asset preso in considerazione.
Successivamente, ho inserito il valore venti come parametro al metodo head come descritto nella riga di codice presente nella seguente riga.
print(df1.head(20))
Il risultato dell’istruzione è riportato nell’immagine sotto.
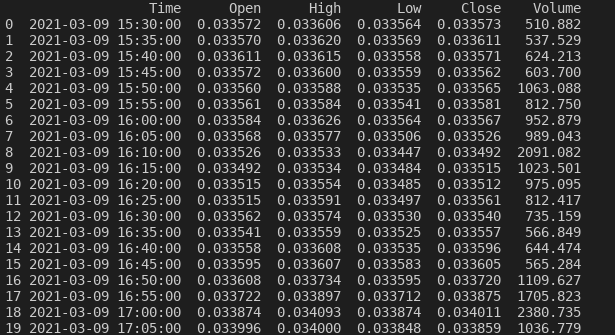
(Un nuovo valore passato al metodo head())
E’ importante sapere, che il valore “Close” definisce i valori dell’asse y nel grafico dell’andamento della pair. Tale valore si estrapola dal dataframe originale comprensivo dei valori OHLCV.
Proseguendo con il resto del codice troviamo le seguenti righe.

(il metodo resample del dataframe df1)
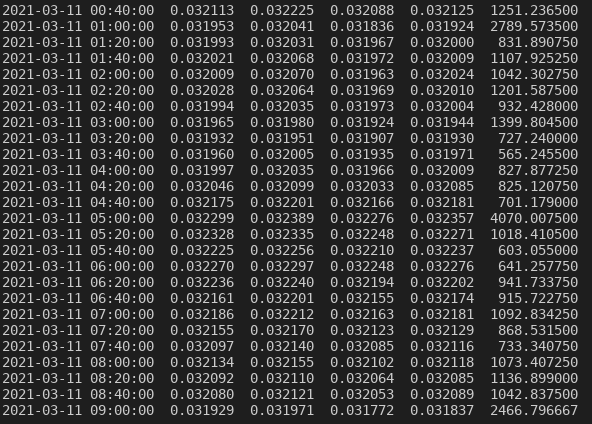
Nella riga trentacinque si utilizza il metodo resample della classe DataFrame per “riorganizzare” i dati secondo diverso intervallo di tempo, il cui valore ottenuto è frutto della media dei dati presenti nell’intervallo voluto. In questo caso ho inserito 10T; Il simbolo T indica i minuti. Se avessi scritto 20T l’asse x sarebbe stata riorganizzata temporalmente in un intervallo di tempo da un dato e l’altro di venti minuti. Il risultato l’ho assegnato al nuovo oggetto di tipo DataFrame df1_daily. Con la riga trentasei ho stampato nel terminale i valori del nuovo DataFrame come mostrato nella figura seguente.
(Ora i dati sono disposti ogni 10 minuti)
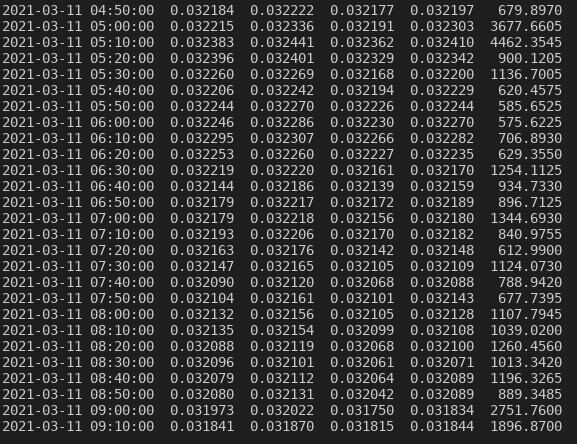
Come vedete i dati sono organizzati secondo intervalli di tempo di dieci minuti. Il dato dei dieci minuti è calcolato secondo la media dei dati presenti all’interno di questo intervallo. Proviamo ora con venti minuti. Quindi, dobbiamo modificare il seguente codice:
df1_risultato = df1.resample(’20T’, on = ‘Time’).mean()
A questo punto vediamo il risultato:
(Resample dei dati a 20 minuti).
Come vedete ora i dati sono organizzati secondo un intervallo di venti minuti.
Ora cerchiamo di capire come visualizzare i dati con un intervallo di tempo di 20T. Con le seguenti istruzioni.

(La visualizzazione dei dati d’interesse).
Nell’immagine precedente, passiamo al metodo plot del Dataframe df1_risultato i seguenti parametri: y e cioè la colonna da rappresentare, figsize, cioè la grandezza della finestra misurata in inches e il titolo che in questo caso è ‘Ethereum Price”. Al parametro y è associato come vedere la colonna ‘Close’ del dataframe. Questa, ci permette di rappresentare l’andamento del prezzo di ETH rispetto al Bitcoin.
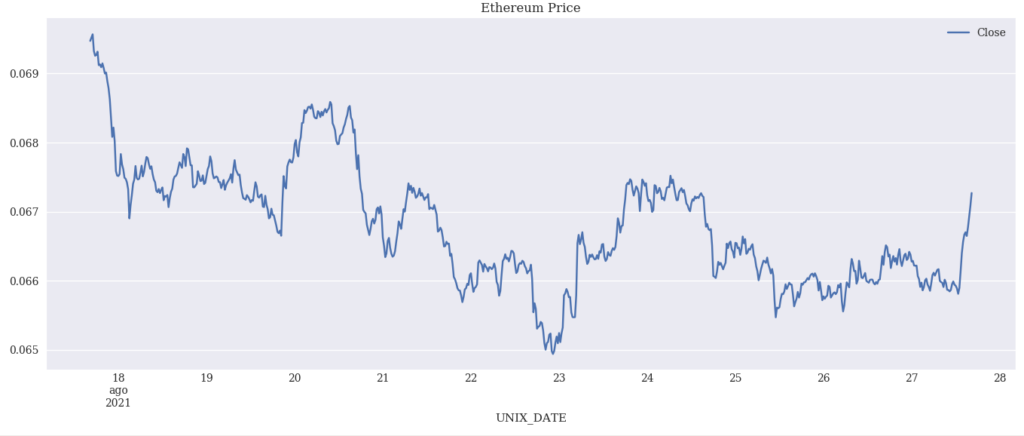
(Andamento della Pair ETH/BTC)
Il risultato è assolutamente interessante. Il grafico è costruito su un intervallo di dati di tempo (asse x) di 20 minuti come definito nel metodo “resample”.
Conclusioni
Abbiamo visto come eseguire il download dei dati relativi alla pair da un exchange con l’utilizzo della libreria ccxt e a come visualizzarli tramite l’aiuto della libreria Matplotlib. Nei prossimi articoli entreremo nel dettaglio dell’applicazione degli algoritmo di machine learning.
Link alle parti seguenti degli appunti di Machine Learning:
Appunti di Machine Learning in ambito finanziario II parte.
Appunti di Machine Learning in ambito finanziario III parte.
Per eventuali domande e integrazioni inviate un e-mail a webmaster@megalinux.cloud. Aiutate a sostenere The Megalinux, l’unico sito nel Web senza pubblicità. Inviate Bitcoin al seguente indirizzo.
3LpoukFpvDHTZPn5qGbLwUzve3rX9zsSq6
