Appunti di Machine Learning in ambito finanziario – II parte –
Ottobre 21, 2021In questa seconda parte di appunti, continueremo a scrivere del codice in Python. Scendendo nel particolare, vedremo una breve introduzione al modello della regressione polinomiale che ci permetterà nella terza parte di individuare il valore della variabile dipendente dal valore della variabile indipendente. Nel nostro caso, come descritto nella prima parte, la variabile dipendente è il prezzo, o meglio l’attributo ‘Close’ della pair considerata, mentre, la variabile indipendente è il tempo distribuito secondo un intervallo ben definito.
Il modello di regressione polinomiale
Come indicato nella parte introduttiva, in questo articolo, leggeremo come calcolare un valore di previsione del prezzo ‘Close’ applicando il modello della regressione polinomiale.
La regressione polinomiale è un tipo di modello della regressione lineare, e può essere rappresentata dalla seguente espressione:
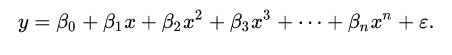
Facendo riferimento all’espressione illustrata nella figura precedente, il nostro caso di esempio utilizza un solo parametro o feature: il prezzo ‘Close’ dell’asset della pair. Il valore di risposta y (variabile dipendente) non è un vettore, ma solo un valore, quindi il tutto diventa abbastanza semplice. Si trovano i coefficienti, e come valore della variabile x (indipendente) si passa il valore dell’intervallo di tempo considerato. Il tutto, servirà a trovare il valore di previsione. Come vedremo, nella terza parte sarà Python a trovare i coefficienti dell’espressione, e quindi a calcolare i valori stimati.
Quanto scritto, si traduce in codice Python. Quindi, iniziamo da dove avevamo lasciato nella prima parte con la lettura e la spiegazione del codice.

(Da Dataframe ad oggetto ndarray).
Nella riga quarantotto si esegue la stampa dei valori della colonna ‘Close’ del dataframe df1_risultato. Questo, ci permetterà di capire la differenza tra i valori del dataframe e i valori presenti in un oggetto ndarray.
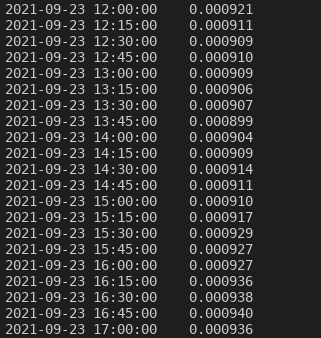
(Stampa della colonna ‘Close’ del dataframe df1_risultato).
Come vedete, la stampa della colonna ‘Close’ del dataframe df1_risultato prevede anche l’associazione del relativo indice, che nel nostro caso corrisponde alla colonna ‘Time’ del dataframe come definito nella prima parte di questi appunti.
A questo punto, proseguiamo con la riga del codice Python quarantanove, ove la proprietà values dell’oggetto Dataframe estrae i dati della colonna ‘Close’ e li salva in un oggetto ndarray. L’oggetto in questo caso viene chiamato ‘l’. Ora i dati sono disposti secondo l’immagine seguente.
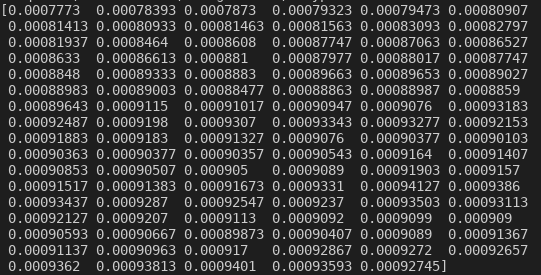
(Stampa dei valori nell’oggetto ndarray l)
Guardando la figura tre, ora i valori della colonna ‘Close’ sono epurati dall’indice del dataframe e disposti in un vettore così da poterli manipolare al meglio.
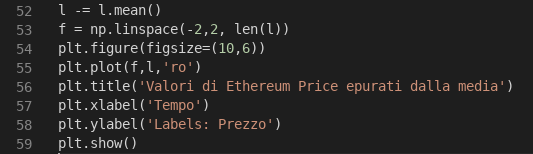
(Rappresentazione dei valori dell’andamento della pair utile epurati dalla media).
Nella riga cinquantadue, ad ogni valore presente nel vettore l viene sottratto il valore di media dei dati del vettore l. Quindi, i valori espressi dal vettore l sono sostanzialmente gli scostamenti rispetto alla media. Nella riga successiva, la cinquantatré, riduciamo ad un intervallo [-2,+2] i valori possibile dell’asse x. L’asse x non conterrà più un valore temporale, ma un valore numerico compresso nell’intervallo -2, +2, però, è sottinteso che lo esprime.
Di seguito i valori del vettore f.
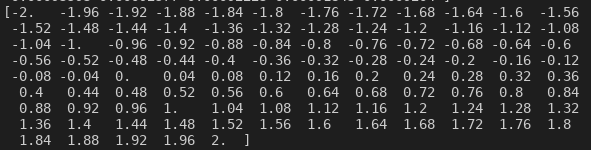
(I valori f dopo l’applicazione del metodo Numpy Linspace)